
【机情无限 精彩毕设】机械2025届毕业设计(论文)中期检查优秀案例分享第十四期——基于神经网络的汽车变速箱轴承故障诊断

学生姓名:刘棋峰
班 级:车辆2021-05班
指导教师:黄海波
毕设题目:基于神经网络的汽车变速箱轴承故障诊断


一、概况
1.选题意义
变速箱轴承的故障诊断通常依赖于对振动信号的分析。由于故障状态下振动信号的非平稳性、复杂性以及噪声的干扰,传统的诊断方法面临很大的挑战。尤其在变速箱这种复杂的机械系统中,轴承故障的诊断更加困难。因此,如何准确、实时地检测变速箱轴承的故障,并对故障类型进行快速判断,成为了当前研究和工程实践中的重要问题。
传统的故障诊断方法如时域分析、频域分析、经验模式分解等,虽然在某些简单的故障情况下有效,但面对复杂、非线性、非平稳的振动信号时,难以取得理想的诊断效果。特别是在多个故障并存或故障逐渐发展的情况下,传统方法的识别精度和鲁棒性受到限制。
基于此,本课题提出利用神经网络等智能算法对变速箱轴承的故障进行诊断。这些智能算法具备强大的数据处理能力,能够有效从复杂的振动信号中提取特征,识别潜在的故障模式,为故障诊断提供新的解决方案。神经网络特别适合处理非线性、高维、噪声干扰严重的数据,通过学习大量的振动信号数据,可以自适应地提取出影响故障诊断的关键特征,从而实现高精度的故障分类和定位。
2. 任务分解
(1)文献查阅与整理:查阅国内外关于轴承故障诊断、振动信号分析、深度学习模型(如CNN、LSTM、Attention)在故障检测中的应用等相关文献,梳理当前主流研究方法与不足,为后续模型设计提供理论支持。同时掌握公开数据集的构成与实验方法,为实验设计打下基础。
(2)数据处理与对比模型建立:使用已有的变速箱轴承故障振动信号数据集,完成信号的读取、切分与归一化处理。搭建多种对比模型(如基本CNN、LSTM网络、Attention模型等)作为基准,验证各模型在无干扰环境下的基本诊断性能,为后续融合模型打基础。
(3)融合模型设计与实现:结合1D卷积神经网络(WDCNN)、LSTM和自注意力机制设计融合模型,提升特征提取、时序建模与特征聚焦能力。根据振动信号的特点设置合适的卷积核大小与步长,完成模型结构搭建、训练与测试流程。
(4)模型优化与鲁棒性分析:引入不同强度的白噪声扰动,以模拟实际工况下的干扰环境,检验模型在高噪声背景下的抗干扰能力。通过对比分析不同模型在抗噪环境下的准确率和稳定性,寻找最优诊断方案,并对模型结构或超参数进行调优。
(5)论文撰写与修改:总结研究中取得的成果与创新点,撰写毕业论文初稿。根据指导老师意见完成多轮修改与补充,整理实验数据与图表,最终形成完整、逻辑清晰、结构规范的毕业论文文档。
3. 已完成工作
(1)据预处理与特征构造: 成功读取公开轴承数据集并处理了轴承状态数据集中的 .mat 文件,对原始振动信号进行归一化处理与滑窗切分操作(步长为512,重叠率为0.5),将一维时间序列转换为统一长度的输入样本,为模型训练奠定基础。
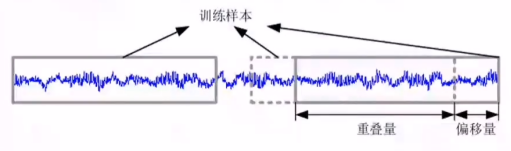
图1 滑窗切分操作原理
(2)模型结构设计与实现:在多轮实验探索的基础上,设计并实现了基于(1DCLA模型)WDCNN + LSTM + Self-Attention的混合模型结构如图3所示:WDCNN模块通过宽核卷积提取低频与局部故障特征,采用多层卷积与池化操作逐步加深网络;LSTM模块用于建模时间序列中的长依赖关系,捕捉设备运行状态的演化过程;Self-Attention模块进一步强化模型对关键时间片段的关注能力,从全局层面对时序特征进行加权聚合。
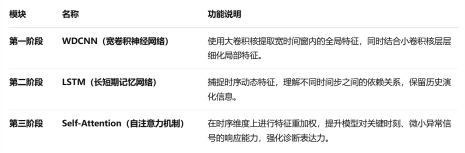
图2 网络结构功能说明

图3 1DCLA模型网络结构
(3)模型训练与优化:构建了完整的训练流程,采用交叉熵损失函数与Adam优化器进行模型优化,并针对一维时间序列信号特点在卷积层参数、池化层结构、LSTM单元数量等方面进行多轮调参实验。同时,构建了模型参数统计函数用于控制网络复杂度。
(4)模型性能初步评估:通过训练集、验证集与测试集划分,完成模型在标准数据集下的性能测试。模型在多类故障状态下均表现出较高的分类精度,如图4所示,训练损失曲线显示出良好的收敛性,模型在约20个epoch后进入稳定收敛阶段,未出现明显过拟合现象。最终模型在测试集上的分类准确率达到99%,显著优于传统的CNN结构,验证了WDCNN+LSTM+Attention混合模型在故障特征提取与识别任务中的有效性与先进性。
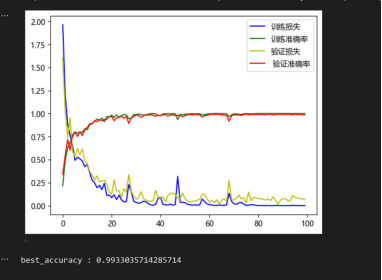
图4 1DCLA模型训练损失曲线
混淆矩阵验证了所提出结构在振动信号分类任务中的可行性。在测试集中,为进一步验证模型对不同类别轴承故障的识别能力,绘制了混淆矩阵(如图5所示)。从混淆矩阵可以看出:模型在各类别上的识别准确率均较高,特别是“正常”类和“滚动体故障”类的识别率接近100%;“内圈故障”与“外圈故障”之间存在少量混淆,可能由于这两类故障在振动信号上的时域特征相似; 整体预测准确率为 99%,表明模型具有良好的多类分类能力。
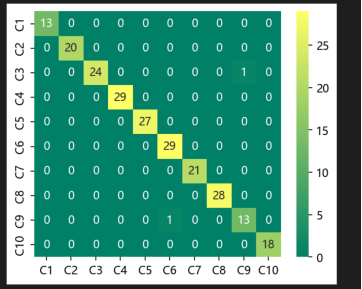
图5 混淆矩阵图
二、下一步工作计划
接下来的工作将集中于以下几个方面:
(1)通过向原始信号添加不同强度的白噪声,模拟工业环境干扰,进一步评估模型在复杂背景下的稳定性和抗噪能力;
(2)对模型结构进行细节优化与超参数调优,包括调整卷积核、LSTM单元数量和Dropout策略,以提升模型鲁棒性与计算效率;
(3)完成可视化分析与多模型对比实验,使用混淆矩阵、各类别准确率等指标系统评估本模型优势;
(4)加快论文撰写进度,聚焦于创新点提炼和实验结果图表的补充,尽快完成初稿并进行修改完善

问题一:你的方法和传统故障诊断方法有什么不同?
回答:传统方法多依赖手工特征,受人为经验限制。我采用WDCNN自动提取局部故障特征,LSTM建模时间依赖关系,Attention机制强化对关键特征的关注,提高了模型对时序信息的理解和分类准确性。
问题二:你的数据集是哪来的?如何划分训练集和测试集?
回答:来自 CWRU(凯斯西储大学)轴承故障数据集和西安交大轴承数据集,是公开广泛使用的振动信号数据集。采用 5:5 和7:2:1 的方式都进行了划分,确保测试集中包含各类故障的代表性样本

回顾过去这段时间的学习与实践,我收获颇丰,不仅提升了理论水平和实践能力,也更加明确了今后努力的方向。
首先,我掌握了大量与智能故障诊断相关的知识,并系统学习了卷积神经网络(CNN)、长短期记忆网络(LSTM)以及注意力机制(Self-Attention)等深度学习技术,理解了它们在处理时间序列振动信号中的应用价值。在模型设计阶段,我反复调试网络结构和参数配置,从中学会了如何结合理论与实际需求进行改进优化。其次,在数据处理和实验搭建过程中,我深入掌握了PyTorch框架的使用,学会了如何进行数据预处理、滑窗切分、模型训练与测试等全流程操作。针对实验室数据较为理想、实际噪声不足的问题,我还尝试往原始信号中添加不同强度的白噪声,以模拟真实工业场景,从而提高模型的鲁棒性。这个过程让我深刻意识到模型泛化能力的重要性,也锻炼了我的工程思维。我也深刻体会到了沟通与协作的重要性。在遇到技术问题和思路瓶颈时,多次向黄海波导师请教,及时获得了有效指导,让毕设工作进行得较为顺利。后续我将根据老师提出的修改建议,继续完善模型设计,优化结构参数,进一步提升诊断精度,并尽快完成论文撰写,力争高质量完成整个毕设任务。