
【机情无限 精彩毕设】机械2025届毕业设计(论文)中期检查优秀案例分享第二十四期——人机交互中基于信息融合的情绪判别

学生姓名:李鑫
班 级:机械2021-05班
指导教师:孟文
毕设题目:人机交互中基于信息融合的情绪判别


一、概况
1.选题意义
随着人工智能和判别自然语言领域的发展,多模态情绪判别(Multimodal Emotion Recognition,MER)这个课题已成为研究热点。该技术通过融合文本、音频和视觉这三类多种模态(主要)信息,只为更全面地理解用户情绪状态,其对应于智能客服、情绪计算等领域展现出广阔的应用前景。然而,由于数据中不同模态间存在明显异质性特征,而这种模态间的分布差异给多模态的有效融合带来了严峻的挑战。当前的研究多聚焦于设计更为复杂的融合机制,却往往忽视了模态表示学习这一关键环节,导致模型性能提升受限。基于这一问题,本文地提出了MIER(Modality-Invariant and Modality-Specific Representations for Multimodal Emotion Recognition)基于共享-私有表示分离的多模态情绪判别模型。该模型的核心是通过同时学习模态不变表示和模态特定表示:前者用于捕捉跨模态的共性特征,后者则保留各模态的独有特性。通过这种双重视角的学习方式,能够实现更高效简洁的多模态信息融合,从而显著提升情绪判别的可行性。本次研究不仅具有重要的理论创新价值,研究成果还可广泛应用于情绪计算、人机交互等实际场景,为构建更智能化的情绪判别系统提供了新的理论支撑。
2.任务分解
基于毕业设计的时间:2024.12.9-2025.5.21(共十七周),整体安排的甘特图如下:

二、已完成工作
1.完成毕业论文前三章内容撰写:绪论、MIER相关技术理论概述和“基于共享-私有表示分离的多模态情绪判别模型”MIER的系统框架阐述。
2.完成两篇外文翻译:《Fusing facial and speech cues for enhanced multimodal emotion recognition》和《Neural correlates of individual differences in multimodal emotion recognition ability》




4.完成MIER的环境部署(基于Anaconda的虚拟环境)及PyTorch平台下模型框架的参数配置,并成功运行基本实现毕业设计MIER模型的相关代码。
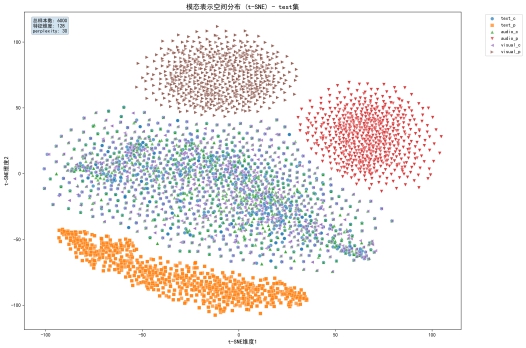
*成功生成多模态表示学习“空间分布TSNE图”,证实系统代码已实现基于共享-私有表示分离的多模态情绪判别模型MIER的最关键步骤——模态表示分离工作:
5.完成数据集CMU-MOSI和CMU-MOSEI的合理划分及项目所需预处理工作,并生成相关评估指标:
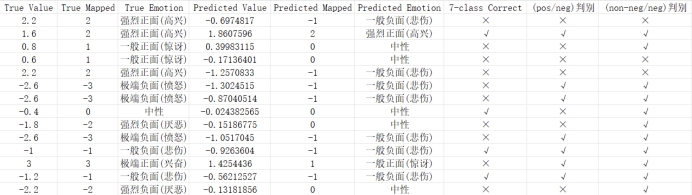
(1)多模态融合质量的实时量化指标判断汇表(验证和测试节选):
![]()
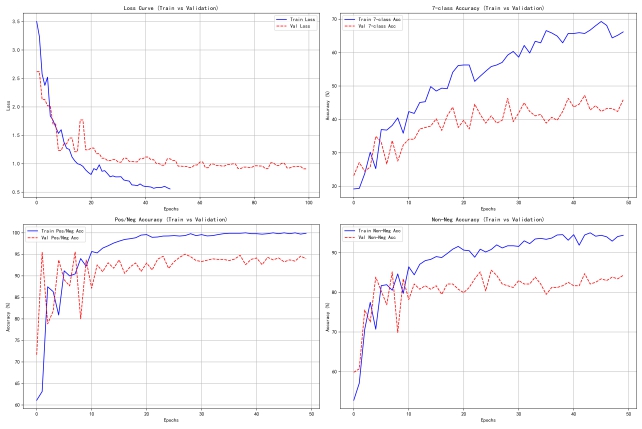
(2)CMU-MOSI随着训练epoch递增的训练模型准确率变化曲线及损失率变化曲线(基于训练-验证):
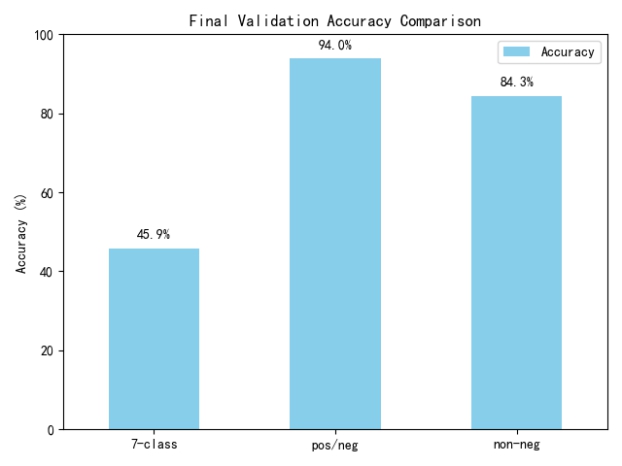
(3)CMU-MOSI训练出最佳epoch准确率柱状图:
(4)best model在分类任务中(七分类、正负二分类和非负,负二分类)的Precision、Recall、F1-Score、accuracy 、macro avg、weighted avg,不仅如此,best model也加入了两个经典回归任务评判指标:定义在情绪强度区间[-3,+3]中,两个数据集MOSI、MOSEI训练后的平均绝对误差MAE(模型预测值与真实值的平均绝对偏差 )和皮尔逊相关系数CORR(评价模型是否能好捕捉情感趋势)。
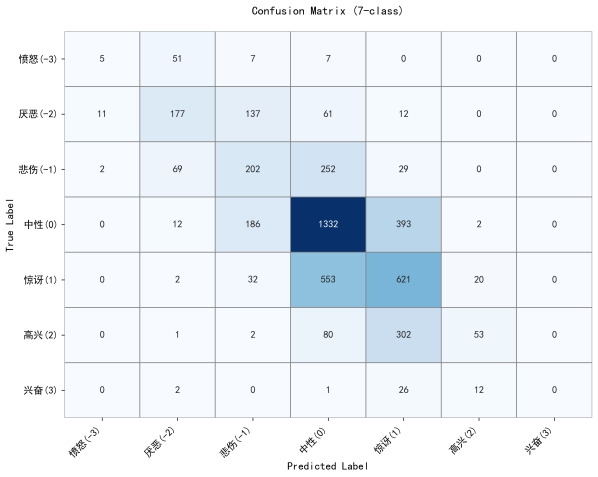
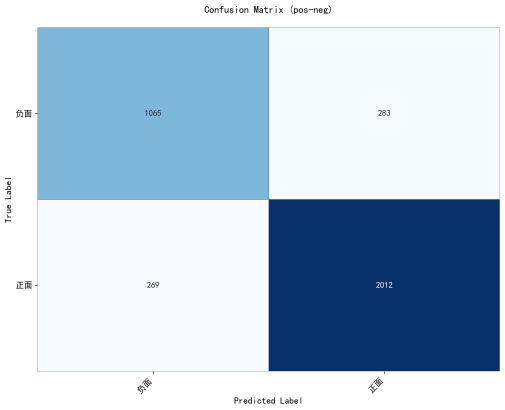
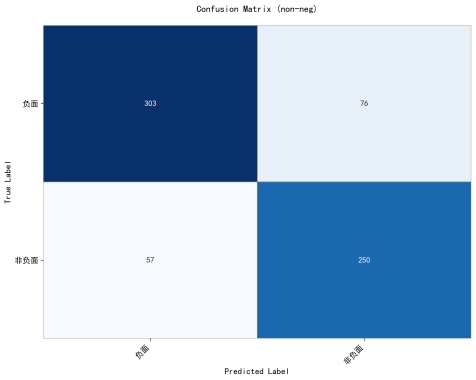
(5)最终的混淆矩阵;
a.七分类(7-class):
b.正/负二分类(pos-neg):
c.非负/负二分类(non-neg/neg):
三、下一步工作计划
1.实验优化与数据增强:
(1)极端样本增强:
通过分析数据集中极端样本的分布特征,采用数据采样、生成对抗网络(GAN)等方法对极端样本进行增强,确保模型在处理极端情况时的鲁棒性和泛化能力。对比增强前后的模型性能,验证增强策略的有效性。
(2)动态边界实现:
设计动态边界机制,根据训练过程中数据分布的变化实时调整边界参数,增强模型对复杂数据的适应性。通过实验验证动态边界对模型性能的提升效果,并分析其对不同数据集的适用性。
(3)优化损失函数:
结合当前输出指标缺陷和设计代码,优化多目标联合损失函数,平衡不同任务之间的权重,提升MIER模型的综合性能。
2.模型训练与结果分析:
(1)分阶段训练:
完善所有设计功能后,依次对 CMU-MOSI 和 CMU-MOSEI 数据集进行深度训练,采用分阶段训练策略,逐步提升模型的性能。通过对比不同阶段的训练结果,分析模型在不同数据集上的适应性和优化方向。
(2)消融实验:
通过对比消融组类:[none]、[no_shared]、[no_private]、[no_adversarial]、[no_cmd]、[no_recon],验证 MIER 系统设计的合理性。分析每个模块对模型性能的影响,确定关键模块的贡献度。
(3)生成可视化图表:
生成最终版本 CMU-MOSI 和 CMU-MOSEI 数据集随着训练 epoch 递增的模型(训练-验证)准确率变化对比曲线和损失率变化对比曲线,以及模态表示学习-空间分布 TSNE 热力图。通过可视化分析,直观展示模型训练过程中的性能变化趋势和模态表示分布特征。
3.系统整合与调试:
(1)关键代码优化:
对系统中的关键代码进行优化,包括算法实现的加速、内存占用的优化以及代码结构的简化。通过性能测试,验证优化后的代码在运行效率和资源利用率上的提升。
(2)整合关键代码:
将优化后的代码模块进行整合,确保各模块之间的兼容性和协同性。通过系统测试,验证整合后的系统在功能完整性和稳定性上的表现。
(3)整理系统文件:
对系统文件进行分类整理,包括代码文件、配置文件、数据文件和文档文件等。通过文件结构的优化,提升系统的可维护性和可扩展性。
4.完成论文与答辩准备:
(1)完成论文初稿:
根据实验结果和系统设计,撰写论文初稿,包括引言、相关工作、方法设计、实验结果和结论等部分。确保论文内容逻辑清晰、结构完整,并符合学术规范。
(2)论文终版修订:
根据导师的反馈意见,对论文初稿进行修订,完善论文的表述和格式,确保论文质量达到学术要求。
(3)完善指导纪要:
整理实验过程中的指导纪要,记录关键实验步骤、问题解决过程和指导建议,为论文撰写和答辩提供支撑材料。
(4)答辩材料准备:
准备答辩所需的材料,包括答辩 PPT、演示视频和答辩提纲等。通过模拟答辩,验证答辩材料的完整性和逻辑性,确保答辩过程顺利进行。

问题一:如何评价模型改进后的效果?
回答:通过对比实验设计方案,与传统的单模态情绪判别模型以及传统的多模态情绪判别模型选用同样的数据集做控制变量对比实验。进而体现MIER模型的优势。
问题二:评价指标是什么?
回答:
1.多模态融合质量的实时量化指标判断汇表(验证和测试)。
2.随着训练epoch递增的模型准确率变化对比曲线及损失率变化对比曲线(基于训练-验证)。
3.best model在分类任务中(七分类、正负二分类和非负,负二分类)的Precision、Recall、F1-Score、accuracy 、macro avg、weighted avg以及最终的混淆矩阵;
4.不仅如此,best model也加入了两个经典回归任务评判指标:定义在情绪强度区间[-3,+3]中,两个数据集训练后的平均绝对误差MAE(模型预测值与真实值的平均绝对偏差 )和皮尔逊相关系数CORR(评价模型是否能捕捉情感趋势)。
问题三:是否能按期完成毕业设计?
本人目前按上述任务分解的整体安排顺利进行,目前已完成前三部分任务并已开始第四部分工作。有信心按期完成本人毕业设计。

通过本次毕业设计,我在多模态情绪识别领域的理论与实践能力均得到了显著提升。在数据处理方面,我完成了CMU-MOSI和CMU-MOSEI数据集的合理划分与预处理工作,并设计了多模态融合质量的实时量化指标,为模型训练奠定了高质量数据基础。在模型评估中,我构建了涵盖分类任务(Precision、Recall、F1-Score等)和回归任务(MAE、CORR)的多维度评估体系,通过对比实验验证了MIER模型在情绪强度预测上的优势。在回答老师提问时,我学会了如何通过控制变量法设计严谨的实验方案,并从分类与回归双任务角度系统性地评价模型性能。此外,通过论文撰写和外文翻译,我掌握了学术表达的规范性,同时在Anaconda环境部署和PyTorch框架配置中提升了工程实践能力。整个过程让我深刻体会到理论与实践结合的重要性,也为未来在多模态领域的研究积累了宝贵经验。